

A look at the data shows that inference is not just overtaking but will soon completely dominate the AI landscape.
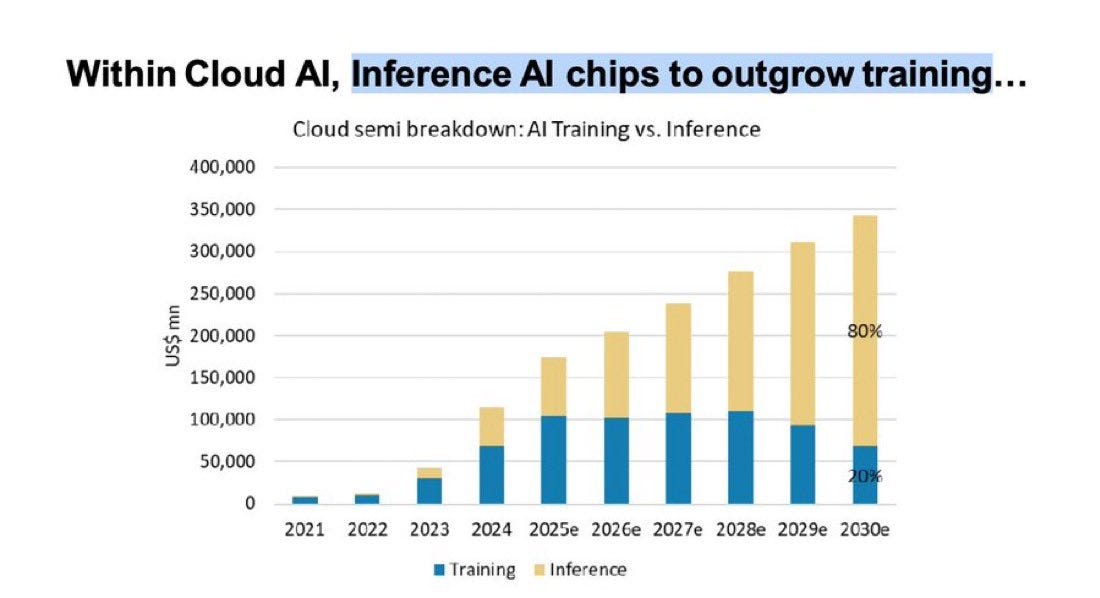
Today, the conversation around AI is dominated by training GPUs—the focus of earnings calls, massive cluster builds, billion-dollar orders, and prestigious benchmarks. However, the balance is set to flip dramatically. By 2030, roughly 80% of all cloud AI semiconductor spending will be for inference, with training accounting for just 20%.
Why? Because once the models are built, the real scaling happens in deployment. Inference is how AI enters the bloodstream of the global economy, becoming a constant, essential function. Think of it this way:
Training is like shooting a movie. It's a massive, one-time (or occasional) production with a huge budget, a large crew, and a specific, intense timeframe. You need a dedicated, powerful set to make it happen.
Inference is like streaming that movie to billions of viewers. Each individual view is a tiny fraction of the original effort, but the sheer volume of views—happening 24/7 across the globe—dwarfs the initial production.
This shift is already visible across industries. For example, a global retailer like Walmart might invest heavily in a new AI model to optimize its supply chain (training), but that model will then be used thousands of times a minute to make real-time decisions on inventory, routing, and pricing at stores worldwide (inference). A single training run enables an endless stream of real-world applications.
Another example is in finance. A bank may spend millions training a fraud detection model using years of historical transaction data. That intense, one-off training event then allows the model to perform inference on every single credit card transaction in real time, making instant decisions to approve or flag billions of payments every day. This continuous, high-volume demand for inference is what will drive its market dominance. Training is episodic; inference is perpetual.
This shift from training to inference has three major consequences that will reshape not just the AI industry but also the global economy, energy markets, and international relations.
Market Power Shifts
The companies that win the inference race won't necessarily be the same ones that dominated the training era. While NVIDIA has been the undisputed champion of high-end training GPUs, the low-power, high-volume demands of inference are opening the door for new players. Companies optimized for inference will capture outsized value.
While hyperscalers like Amazon, Google, and Microsoft have been major customers for NVIDIA's A100 and H100 GPUs for training, they're also creating their own in-house AI chips, like Google's TPU and Amazon's Inferentia. These chips are purpose-built for efficient, low-cost inference at a massive scale, reducing their dependence on external suppliers like NVIDIA. Similarly, companies like AMD and startups like Groq are carving out niches by creating silicon and software optimized for fast, real-time inference, posing a direct challenge to the incumbent leader.
Energy Becomes the Bottleneck
While AI training uses enormous amounts of energy, the energy demands of planetary-scale inference will dwarf it. Every single query, transaction, and decision—billions of them daily—requires a small amount of energy. The sheer volume of these requests, however, turns data centers into quasi-utilities. The real question for the next decade won't be which chip is most powerful, but which can deliver a given number of inferences per watt.
The energy footprint of inference is already a significant concern for data center operators and a strategic issue for companies. For instance, if every single online search were a single AI inference query, it would consume an estimated 29 TWh of electricity per year, roughly the amount used by an entire country like Ireland. As AI becomes embedded in everything from autonomous vehicles to smart systems, the aggregate energy consumption of inference will become a critical constraint on technological growth.
Geopolitics of Deployment
Training clusters can be geographically concentrated in a handful of massive, secure data centers. Inference, however, demands distribution. The need for low-latency, real-time AI means that the compute power must be closer to the user, creating a global network of "AI factories," sovereign data centers, and regional compute zones.
This creates new geopolitical dynamics. Countries are now competing to host AI infrastructure, viewing it as a critical component of national security and economic sovereignty. We're already seeing this play out with the U.S.-Gulf partnerships, where countries with vast capital and energy resources, such as Saudi Arabia and the UAE, are investing billions to build their own AI infrastructure.
For now, the contest is about who can train the biggest model. Soon, it will be about who builds and secures the networks that run them. Training proves you can build; inference is where that capability actually shapes the world. The real question isn’t model size anymore, but who can deploy them broadly, efficiently, and securely.
That is the true frontier of compute.